Paper: Meta-Harness
This is a pretty interesting paper on how we can improve the performance of LLM outputs by iterating on the harness. For quite some time, harness engineering was mostly done manually: the maintainer would inspect failures, adjust heuristics, and iterate on a small number of examples. It was a very manual and limited process. This paper explores how that process can be automated.
Pure text optimisations, such as updating the system prompt, are not enough for a few reasons:
- The feedback is usually heavily condensed, which means it can miss key details.
- Some optimisation methods only rely on a scalar score, with no qualitative nuance.
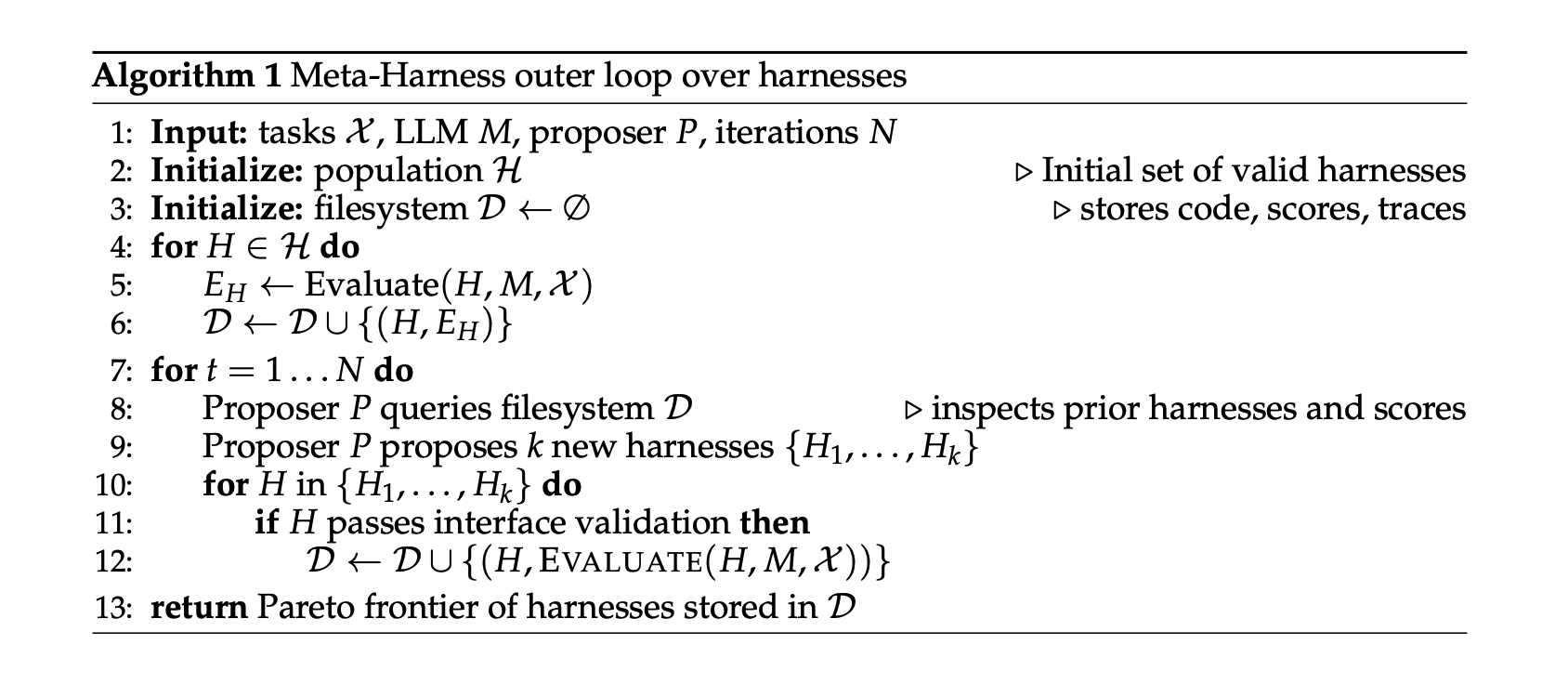
The idea of the paper is fairly simple. The system has three main components:
- A filesystem containing all previous harness versions, along with reasoning traces, failure logs, and evaluation scores.
- A proposer coding agent, which needs to be able to invoke developer tools and modify code.
- A search loop. Using the proposer agent and the filesystem, the system runs an evolution loop for a fixed number of iterations, proposing newer harnesses and adding them back into the filesystem. At the end, it selects the best harnesses for the tasks being evaluated.
There are also a few key design features that make this work:
- The proposer is a coding agent rather than a raw LLM. This matters because the total size of the files in the filesystem will most likely exceed the context window. Instead of loading everything at once, the agent needs to make calls like
grepto identify relevant parts of the files and bring only those into context. - The proposer can diagnose issues, decide what to inspect, and choose what to fix. An alternative would have been to use fixed search heuristics, but the authors avoid that because Meta-Harness can improve automatically as coding agents become more capable. This turns the process into iterative debugging of a system, rather than just prompt generation.
- Another important design choice is storing the full execution traces in the filesystem. Instead of only knowing that a harness failed, the proposer can infer why it failed and how earlier design choices contributed to that outcome. In that sense, the system is not just doing search, but also solving a credit assignment problem over long horizons.
- The filesystem is not just storage; it also acts as an external memory and retrieval system. The system is not simply using more context; it is using adaptive access to context. Rather than loading everything into the prompt, it chooses what to retrieve and inspect.
Thoughts about this
I feel this pattern will be hard to use for generic harnesses and is more likely to work well for tasks that are similar in nature. That makes sense, because when tasks differ too much, it becomes much harder to improve the harness in a way that transfers cleanly across all of them.
I also like that the paper does not optimise purely for accuracy, but also considers context cost. That trade-off matters in practice, especially for long-running systems where a stronger harness is not necessarily better if it becomes too expensive to run.
Another thing I realised is that the whole system depends heavily on the quality of the proposer. Since it needs to diagnose failures, inspect the right parts of the filesystem, and run the correct commands, the proposer has to be strong enough not to hallucinate or degrade the search quality.
More broadly, this paper seems to reflect a bigger paradigm shift. We used to focus mainly on improving models by tweaking the weights, but now there is increasing focus on improving the system around the model, whether through memory, retrieval, orchestration, or harness design.
It also seems computationally intensive, since each iteration requires evaluation. In that sense, it feels similar to an AutoML-style search, where compute is being spent not just on inference, but on discovering better system designs.
It also bears some resemblance to Ralph Loop and AutoResearch. More generally, there seems to be a growing trend towards improvement loops, where agents are used not just to produce outputs, but to iteratively improve the surrounding system itself. I would not be surprised if this becomes a more standard pattern for building high-performance LLM systems.