Had the opportunity to listen in to a talk from Jun Rao, one of Kafka’s original creators, about Queues for Kafka, a new consumption model powered by share groups. This was very coincidental as just a few days ago, I was reading the Kafka paper and the design considerations and one of the points that I flagged out was actually a motivating factor for Queues.
Consumer Groups
To understand Queues, we first need to understand Consumer Groups, Kafka’s initial answer to this question “How do I parallelize the processing of one topic with multiple workers/consumers”
Consumer groups is essentially a group of consumers. Kafka assigns topic partitions across consumers in that group:
Topic: orders
Partitions: P0 P1 P2 P3
Consumer group: payment-service
Consumer A -> P0, P1
Consumer B -> P2
Consumer C -> P3The key thing to note is that each partition is only owned by one consumer at a time. This was considered gold standard at that time for a couple of reasons
- Strong ordering. Since only one consumer reads from the partition, we can enforce that the consumption is being done in order. This is useful for certain use cases in Kafka especially when a downstream consumer is maintaining state or applying events to a state machine
- It doesn’t need to track individual message but just offsets
But there is a huge limitation. Since one partition can only be actively consumed by one consumer in that group, the number of consumers you can have is bounded by the number of partitions that you have.
This is fine for stream processing where we just want to continuously process an ordered stream of events and maintain correct state. Usually, events are partitioned by a logical key, such as user_id, account_id, order_id, or device_id. This means all events for the same entity land in the same partition and can be processed in order, while different entities can still be processed in parallel. However if we want to just process as many messages as fast as possible similar to a Queue rather than stream, the common practice is to over partition to get more worker parallelism.
Share Groups
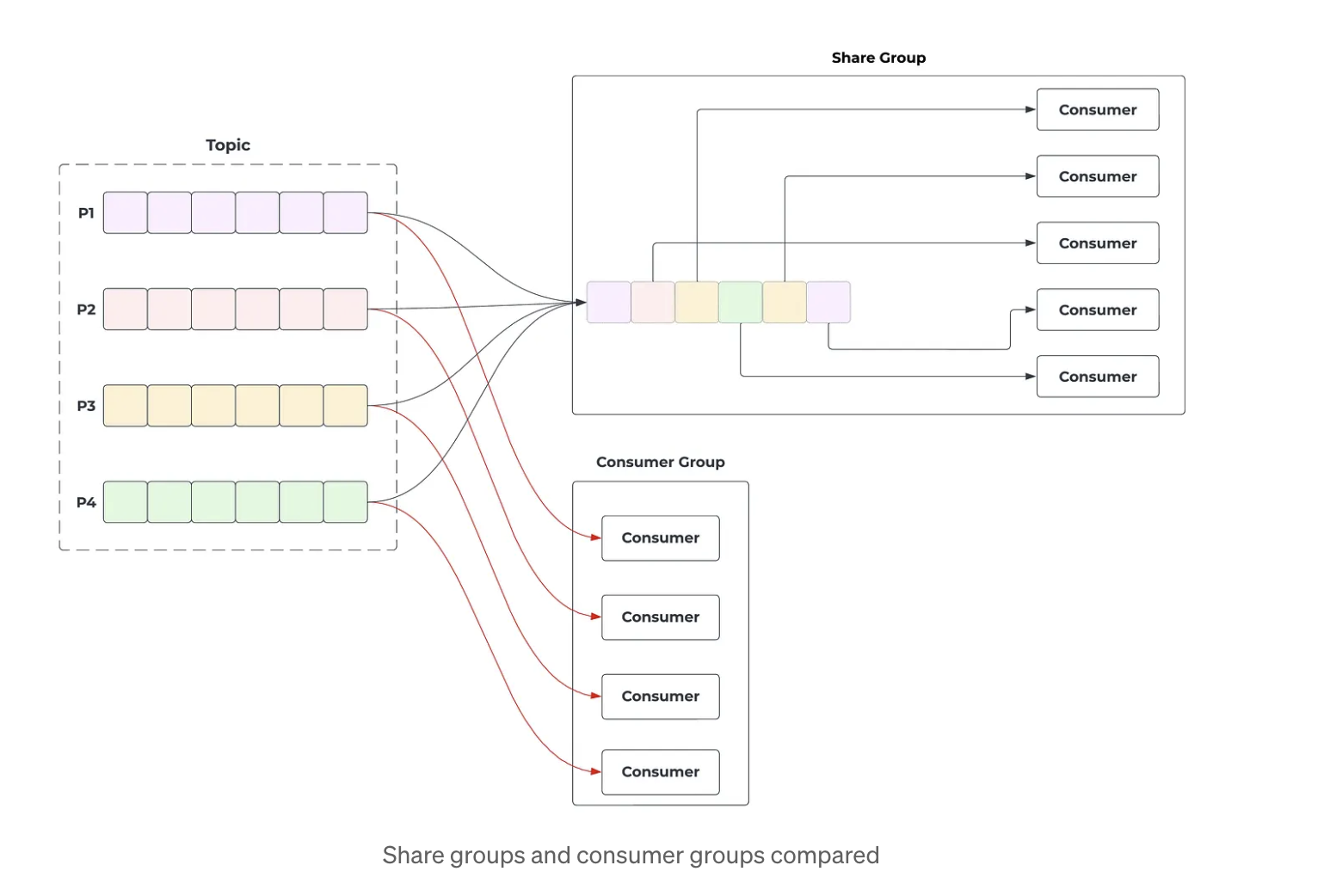
The beauty of share groups is that multiple consumers in a share group can process records from the same partitions. This allows us to have more consumers than the number of partitions. As shown in the diagram, a share group can have in-flight records originating from multiple partitions at the same time. These records are then distributed across consumers, so different consumers may process records from the same partition or from different partitions.
However, enabling this queue-like model is not as simple as just letting more consumers read from the same partition. Classic consumer groups only need to track progress at the partition level using committed offsets. Share groups need finer-grained tracking because individual records can now be acquired, acknowledged, retried, or released independently.
This is where share partitions come in - a new construct for Share Groups to improve the book keeping.
Share Partitions and In Flight Records
A share partition is Kafka’s tracking state for one topic partition + one share group.

There is a lot of things going on in this picture but let me try to slowly break it down. Each box is a record offset in the topic partition. Each record has a state and delivery count. I will explain what these two are in a bit. There are also two key pointers in this partition
- SPSO = Share Partition Start Offset
- Basically anything before this offset is fully resolved and consumed and there is no need for tracking
- SPEO = Share Partition End Offset
- Latest offset currently admitted into tracking
To put things simply, SPSO moves forward when old work is done. SPEO moves forward when new work is admitted.
States and Delivery Count
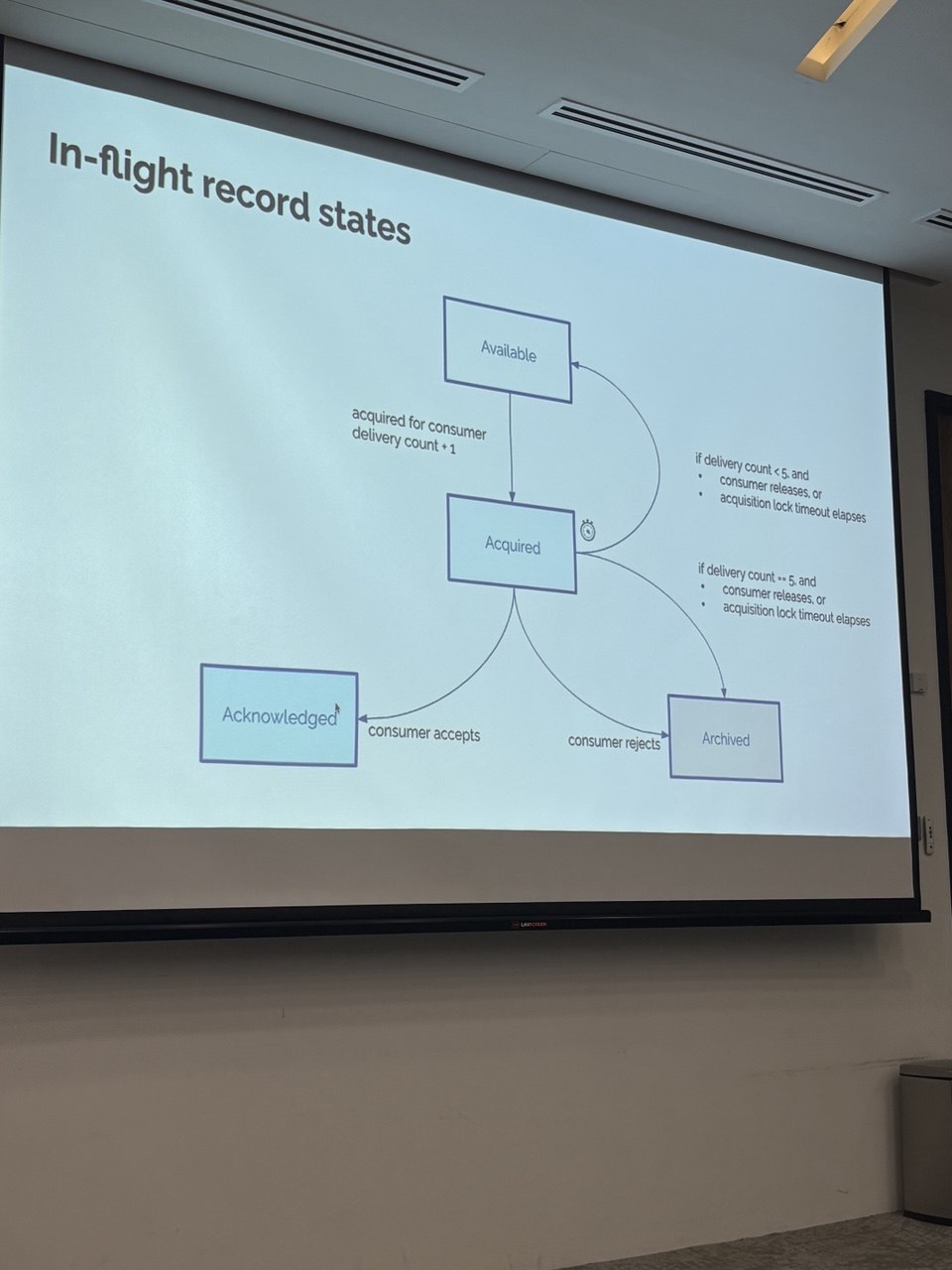
There are 4 main states - available, acquired, acknowledged and archived. When the message enters the partition and is eligible to be delivered, it becomes available. When a consumer fetches the record, Kafka gives the record to a consumer and delivery count increase by 1. Delivery count is basically the number of times we attempt to deliver this message to the consumer.
If the consumer manages to process the record successfully, the state becomes acknowledged and we can move the SPSO pointer. But if the consumer rejects it, it goes to Archived where the message is not delivered. Something to note is that when it goes to Archived, it becomes lost and cannot be retrieved.
Some interesting cases exist if the message is in acquired stage. If we have not attempted to deliver that message more than x times and if either the message stays at being acquired for too long or if the consumer releases (example if the consumer dies), it goes back to being available and another consumer can work on it. But if we tried to deliver it more than x times, it becomes archived.
Coordination
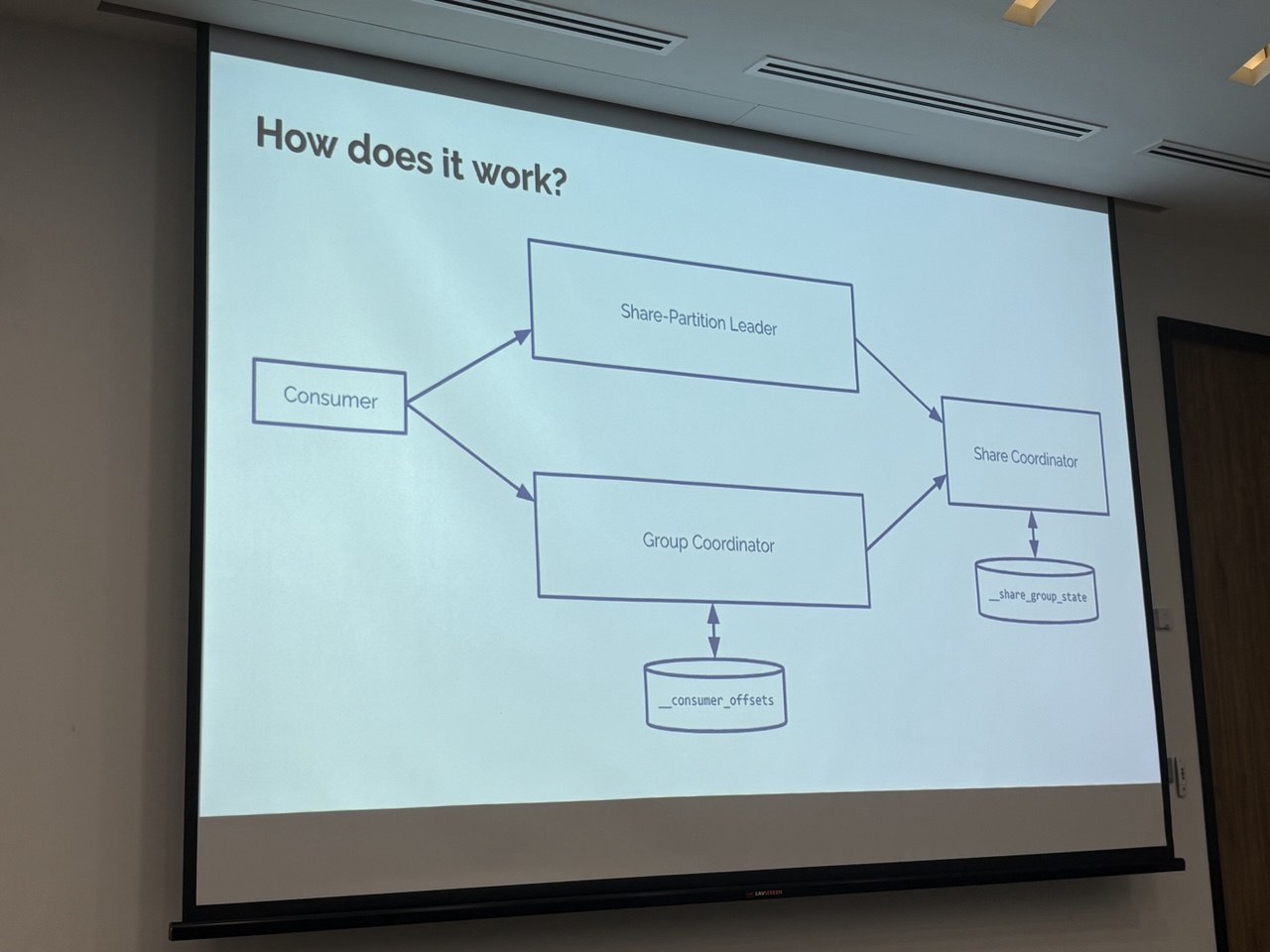
One of the most important parts for this to work is the coordination. We need both normal group coordination and new per-record delivery-state coordination.
Consumer
Your application worker that joins the share group, fetches records/messages and acknowledge. The consumer will then talk to two broker side components - Group Coordinator and Share-Partition Leader
Group Coordinator
The Group Coordinator is responsible for managing the group itself. Some stuff that they store
- Which consumers are in the share group?
- Are they alive?
- What topics/partitions is the group consuming?
- How is group membership coordinated?
The metadata for this and the committed offsets are stored in __consumer_offsets
Share-Partition Leader
The Share-Partition Leader manages delivery for a specific share partition. It stores information like
- Which records are available?
- Which records are acquired?
- Which consumer has acquired them?
- Did the acquisition lock timeout?
- Was the record acknowledged?
- Should it be retried?
- Should it be archived?
So when a consumer asks for a record, it can handle the logic to give a certain record to a certain consumer
Share Coordinator
The Share Coordinator is responsible for persisting share-group/share-partition state. If the Share-Partition Leader goes down, we still want to start from the point it went down. So we need to remember things like
offset 100 -> acknowledged
offset 101 -> acquired, delivery count 2
offset 102 -> archived
SPSO = 98
SPEO = 120These information are persisted to a internal topic
Conclusion
Overall, the main idea is that share groups shift Kafka from just tracking partition-level progress with offsets to tracking record-level delivery state. This is what allows multiple consumers to process records from the same partition without stepping on each other.
But it currently has its fair share of limitations.
-
No built-in dead-letter queue yet
- If a record is archived, it is no longer eligible for delivery. Without a dead-letter queue, there is no clean built-in place to inspect or reprocess failed records later.
-
No strict ordering guarantee
- Since records from the same partition can be acquired and processed by different consumers, they may complete out of order. This is different from classic consumer groups, where one consumer owns a partition and processes records sequentially.
-
At-least-once semantics
- A record may be delivered more than once, especially if a consumer fails after processing the record but before acknowledging it. We still need to write the deduplication process ourselves
However, these limitations are actively worked on by the Kafka team.
I like how Kafka didn’t replace it’s old log based model but refactor the system and use what is useful to build a new system with queue like semantics. This seems to be a very good example of how complex systems might evolve as time goes by. Despite having a very good design for Kafka’s original use case, as we have newer workloads, there are limitations that surfaced requiring Kafka to evolve. Share groups, i would say is a rather elegant attempt at fixing these limitations without giving up the core values of the product: append-only logs, durability and replayability.